
全面掌控Linux进程与安全:从基础管理到高级防护技巧
1.介绍
1.什么是进程
比如: 开发写的代码我们称为程序,那么将开发的代码运行起来。我们称为进程。
总结一句话就是: 当我们运行一个程序,那么我们将运行的程序叫进程。
PS1: 当程序运行为进程后,系统会为该进程分配内存,以及进程运行的身份和权限。
PS2: 在进程运行的过程中,系统会有各种指标来表示当前运行的状态。
2.程序和进程的区别
1.程序是数据和指令的集合,是一个静态的概念。比如/bin/ls、/bin/cp等二进制文件。同时程序可以长期存在系统中。
2.进程是程序运行的过程,是一个动态的概念。进程是存在生命周期的概念的,也就是说进程会随着程序的终止而销毁,不会永久存在系统中。
3.进程的生命周期
生命周期就是指一个对象的生老病死。用处很广。

当父进程接收到任务调度时,会通过fock派生子进程来处理,那么子进程会继承父进程属性。
1.子进程在处理任务代码时,父进程会进入等待状态中…
2.子进程在处理任务代码后,会执行退出,然后唤醒父进程来回收子进程的资源。
3.如果子进程在处理任务过程中,父进程退出了,子进程没有退出,那么这些子进程就没有父进程来管理了,就变成僵尸进程。
PS: 每个进程都父进程的PPID,子进程则叫PID。
例: 假设现在我是蒋先生(system进程)….故事持续中…..
2.监控进程状态
程序在运行后,我们需要了解进程的运行状态。查看进程的状态分为: 静态和动态两种方式
1.使用ps命令查看当前的进程状态(静态)
1)示例、ps -aux常用组合,查看进程 用户、PID、占用cpu百分比、占用内存百分比、状态、执行的命令等
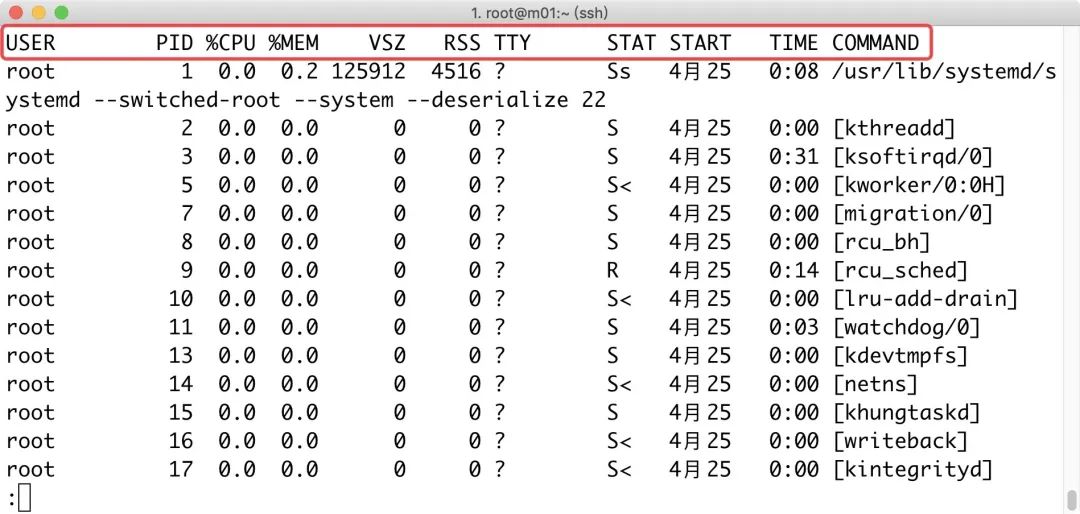
| 状态 | 描述 |
|---|---|
| USER | 启动进程的用户 |
| PID | 进程运行的ID号 |
| %CPU | 进程占用CPU百分比 |
| %MEM | 进程占用内存百分比 |
| VSZ | 进程占用虚拟内存大小 (单位KB) |
| RSS | 进程占用物理内存实际大小 (单位KB) |
| TTY | 进程是由哪个终端运行启动的tty1、pts/0等 ?表示内核程序与终端无关(远程连接会通过tty打开一个bash:tty) |
| STAT | 进程运行过程中的状态 man ps (/STATE) |
| START | 进程的启动时间 |
| TIME | 进程占用 CPU 的总时间(为0表示还没超过秒) |
| COMMAND | 程序的运行指令,[ 方括号 ] 属于内核态的进程。 没有 [ ] 的是用户态进程。systemctl status 指令 |
2.STAT状态的S、Ss、S+、R、R、S+等等,都是什么意思?
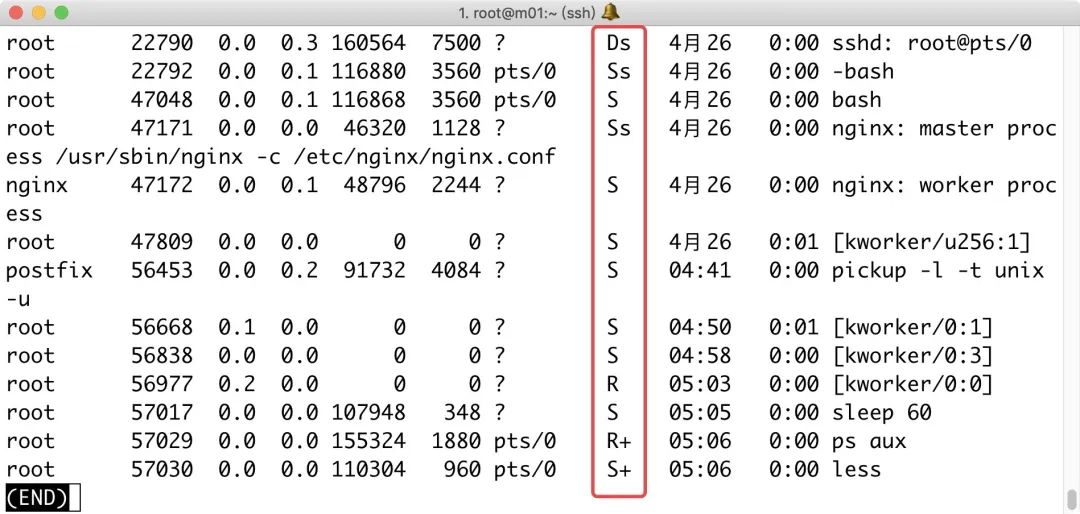
| STAT基本状态 | 描述 | STAT状态+符号 | 描述 |
|---|---|---|---|
| R | 进程运行 | s | 进程是控制进程, Ss进程的领导者,父进程 |
| S | 可中断睡眠 | < | 进程运行在高优先级上,S<优先级较高的进程 |
| T | 进程被暂停 | N | 进程运行在低优先级上,SN优先级较低的进程 |
| D | 不可中断睡眠 | + | 当前进程运行在前台,R+该表示进程在前台运行(正在io操作,一旦停止,数据丢失) |
| Z | 僵尸进程 | l | 进程是多线程的,Sl表示进程是以线程方式运行 |
案例一、PS命令查看进程状态切换
#1.在终端1上运行vim[root@lqz ~]# vim oldboy#2.在终端2上运行ps命令查看状态[root@lqz ~]# ps aux|grep oldboy #S表示睡眠模式,+表示前台运行root 58118 0.4 0.2 151788 5320 pts/1 S+ 22:11 0:00 oldboyroot 58120 0.0 0.0 112720 996 pts/0 R+ 22:12 0:00 grep --color=auto oldboy#在终端1上挂起vim命令,按下:ctrl+z#3.回到终端2再次运行ps命令查看状态[root@lqz ~]# ps aux|grep oldboy #T表示停止状态root 58118 0.1 0.2 151788 5320 pts/1 T 22:11 0:00 vim oldboyroot 58125 0.0 0.0 112720 996 pts/0 R+ 22:12 0:00 grep --color=auto oldboy
案例二、PS命令查看不可中断状态进程
#1.使用tar打包文件时,可以通过终端不断查看状态,由S+,R+变为D+[root@lqz ~]# tar -czf etc.tar.gz /etc/ /usr/ /var/[root@lqz ~]# ps aux|grep tar|grep -v greproot 58467 5.5 0.2 127924 5456 pts/1 R+ 22:22 0:04 tar -czf etc.tar.gz /etc/[root@lqz ~]# ps aux|grep tar|grep -v greproot 58467 5.5 0.2 127088 4708 pts/1 S+ 22:22 0:03 tar -czf etc.tar.gz /etc/[root@lqz ~]# ps aux|grep tar|grep -v greproot 58467 5.6 0.2 127232 4708 pts/1 D+ 22:22 0:03 tar -czf etc.tar.gz /etc/
查看进程 ps
ps [options]
支持的命令格式
unix格式:-h -e
BSD格式:a,x,u
GNU长格式:--help
选项
[root@s22 ~]#ps PID TTY TIME CMD 28019 pts/4 00:00:00 ps 83674 pts/4 00:00:00 bash pid 终端 当前命令占用cpu的时间 命令 a 所有的终端 x 包括不连接终端的终端 u 显示进程详细信息 f 显示进程树 k 指定排序方式 ,默认是递增,如果想递减,则需要在排序的字段上加上- o 指定显示的属性,不能跟u同时使用 L 获取支持的选项, -L 显示线程 -e 相当于 ax -f 显示详细信息,相当于u -F 显示更详细信息 -H 显示树状结构 -U username 获取指定的用户信息 常用选项: aux -ef -eFH
ps输出属性
VSZ 虚拟内存(程序认为可以获取到的)
RSS 实际内存
psr cpu编号
STAT 状态
%cpu cpu的占用率
%mem 内存的占用率
根据名称来查询进程
pidof name [root@s22 ~]#pidof python 1169 825
2.使用top命令查看当前的进程状态(动态)
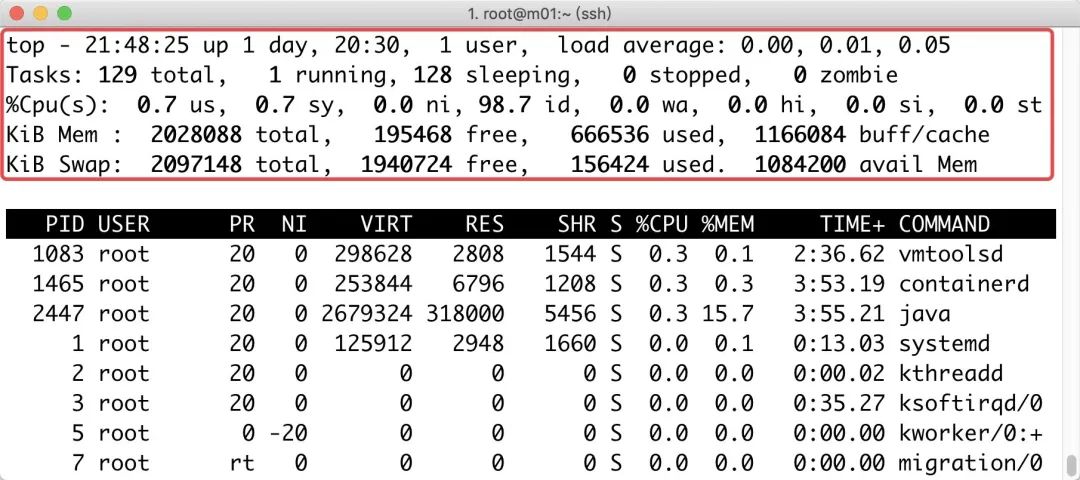
| 任务 | 含义 |
|---|---|
| Tasks: 129 total | 当然进程的总数 |
| 1 running | 正在运行的进程数 |
| 128 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| %Cpu(s) | 平均cpu使用率,按1 查看每个cup具体状态 |
| 0.7 us | 用户进程占用cpu百分比 |
| 0.7 sys | 内核进程占用百分比 |
| 0.0 ni | 优先级进程占用cpu的百分比 |
| 98.7 id | 空闲cup |
| 0.0 wa | CPU等待IO完成的时间,大量的io等待,会变高 |
| 0.0 hi | 硬中断,占的CPU百分比 |
| 0.0 si | 软中断,占的CPU百分比 |
| 0.0 st | 虚拟机占用物理CPU的时间 |
# w load average:平均负载 一分钟,5分钟,15分钟 04:05:43 up 11:35, 3 users, load average: 0.00, 0.01, 0.05 # uptime 04:06:21 up 11:35, 3 users, load average: 0.00, 0.01, 0.05
PS: 如何理解中断这个东西
top 常见指令
| 字母 | 含义 |
|---|---|
| h | 查看帮出 |
| 1 | 数字1,显示所有CPU核心的负载 |
| z | 以高亮显示数据 |
| b | 高亮显示处于R(进行中)状态的进程 |
| M | 按内存使用百分比排序输出 |
| P | 按CPU使用百分比排序输出 |
| q | 退出top |
# 第三方top htop,top高级:yum install htop -y iftop网卡流量:yum install iftop -y glances,直观的显示:yum install glances -y -rz上传文件,可以动态看到,网卡情况
下载新repo 到/etc/yum.repos.d/
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
Epel 镜像,第三方软件库
htop,top高级:yum install htop -y iftop网卡流量:yum install iftop -y glances,直观的显示:yum install glances -y -rz上传文件,可以动态看到,网卡情况
uptime
[root@s22 ~]#uptime 09:17:40 up 1 day, 22:19, 5 users, load average: 2.14, 1.59, 0.84 当前时间 当前服务器运行时长 当前的在线用户数 cpu的负载 1分钟 5分钟 15分钟 cpu平均负载:在特定时间之内cpu运行的平均进程数,不超过cpu核心数的2倍认为为良好
top
首部信息
uptime信息 l 显示与隐藏
tasks :进程总数,运行,睡眠数,停止数,僵尸进程 t
cpu信息: %Cpu(s): 0.3 us, 4.6 sy, 0.0 ni, 95.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
用户空间 系统空间 nice值 空闲 等待 硬中断 软中断 虚拟机偷走时间
内存信息 m
cpu分别显示 1(数字)
排序:
模式是cpu的占用率 P
M:内存占用率
T: cpu的占用时间
退出:q
修改刷新频率:s,默认是3秒
杀死进程:k,默认是第一个
W 保存文件
选项:
-d 刷新时间
-b 显示所有的信息
-n # 指定刷新#次后退出
htop
epel源
3. 系统工具(epel三方库下载),性能分析
free
显示内存
-b 字节 -k kb -m mb -g gb -h 人类易读方式 -c # 刷新次数
vmstat
vmstat [options] [delay [count]] [root@s22 ~]#vmstat 1 3 每秒刷新一次,刷新3次 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 37028 162708 0 808588 0 0 8 6 34 34 0 2 97 0 0 0 0 37028 162560 0 808588 0 0 0 0 4535 6893 1 5 95 0 0 0 0 37028 162544 0 808588 0 0 0 0 4463 6772 0 5 95 0 0 procs: r:正在运行的进程个数 b:阻塞队列的长度 memory: swapd: 虚拟内容大小 free: 空闲物理内存的大小 buff:用于buff的大小 cache:用户cache的大小 swap: si:从磁盘交换到内存的数据速率(kb/s) so: 从内存交换到磁盘的数据速率(kb/s) io: bi: 从磁盘读取到系统的速率(kb/s) bo: 从系统写入到磁盘的速率(kb/s) system: in:中断频率 cs:进程之前切换的频率 cpu: us sy id wa st
iostat
查看磁盘读写速度
iostat 1 10
dstat 查看所有
-c cpu -d 硬盘 -m 内存 -n 网络 -p 进程 -r io请求 -s swap --top-cpu 显示占用cpu最多的进程 --top-io 显示占用io最多的进程 --top-mem 显示占用内存最多的进程 --tcp 显示tcp的信息 --udp 显示udp的信息
iftop 显示网卡的流量
4.管理进程状态,进程的管理工具
当程序运行为进程后,如果希望停止进程,怎么办呢? 那么此时我们可以使用linux的kill命令对进程发送关闭信号。当然除了kill、还有killall,pkill
1.使用kill -l列出当前系统所支持的信号

虽然linux支持信号很多,但是我们仅列出我们最为常用的3个信号
| 数字编号 | 信号含义 | 信号翻译 |
|---|---|---|
| 1 | SIGHUP | 通常用来重新加载配置文件,重新读取一次参数的配置文件 (类似 reload) |
| 9 | SIGKILL | 强制杀死进程(有状态的服务(存磁盘的,如mysql)强制停止可能会导致下次起不来) |
| 15 | SIGTERM | 终止进程,默认kill使用该信号 |
1.我们使用kill命令杀死指定PID的进程。
#1.给 vsftpd 进程发送信号 1,15[root@lqz ~]# yum -y install vsftpd[root@lqz ~]# systemctl start vsftpd[root@lqz ~]# ps aux|grep vsftpd#2.发送重载信号,例如 vsftpd 的配置文件发生改变,希望重新加载[root@lqz ~]# kill -1 9160#3.发送停止信号,当然vsftpd 服务有停止的脚本 systemctl stop vsftpd[root@lqz ~]# kill 9160#4.发送强制停止信号,当无法停止服务时,可强制终止信号[root@lqz ~]# kill -9 9160
2.Linux系统中的killall、pkill命令用于杀死指定名字的进程。
我们可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀死的进程,我们还需要在之前使用ps等命令再配合grep来查找进程,而killall、pkill把这两个过程合二为一,是一个很好用的命令。
#例0、通过服务名称杀掉进程[root@lqz ~]# vim nginx.conf # 修改为worker_processes 10;[root@lqz ~]# kill -1 26093 # 平滑reload nginx,可以看到很多ngixn进程[root@lqz ~]# kill 26121 # 杀掉一个子进程,会迅速的被master启动起来,只是id号不一致了[root@lqz ~]# kill 26093 # 主进程,子进程都会被杀掉#例1、通过服务名称杀掉进程[root@lqz ~]# pkill nginx[root@lqz ~]# killall nginx#例2、使用pkill踢出从远程登录到本机的用户,终止pts/0上所有进程, 并且bash也结束(用户被强制退出)[root@lqz ~]# pkill -9 bash# 一般程序都会有自己的启动和停止/usr/local/nginx/sbin/nginx -h
kill
向进程发送信号,实现对进程的管理,每个信号,对应不同的值,对应不同的含义,不区分大小写
查询可用信号:kill -l
常用信号:
1) sighub 不需要关闭程序,重新加载配置文件
2)sigint 终止进程,相当于ctrl+c
9) sigkill 强制杀死进程
15)sigterm 终止正在运行的进程
18)sigcont 继续运行
19)sigstop 后台休眠
按照pid: kill-n pid
按照名称:killall -n name
按照名称:pkill -n name
5.管理后台进程,作业管理
1.什么是后台进程
通常进程都会在终端前台运行,一旦关闭终端,进程也会随着结束,那么此时我们就希望进程能在后台运行,就是将在前台运行的进程放入后台运行,这样及时我们关闭了终端也不影响进程的正常运行。
2.我们为什么要将进程放入后台运行
比如:我们此前在国内服务器往国外服务器传输大文件时,由于网络的问题需要传输很久,如果在传输的过程中出现网络抖动或者不小心关闭了终端则会导致传输失败,如果能将传输的进程放入后台,是不是就能解决此类问题了。
3.使用什么工具将进程放入后台
早期的时候大家都选择使用&符号将进程放入后台,然后在使用jobs、bg、fg等方式查看进程状态,但太麻烦了。也不直观,所以我们推荐使用screen。
1.jobs、bg、fg的使用(强烈不推荐,了解即可)
[root@lqz ~]# sleep 3000 & //运行程序(时),让其在后台执行[root@lqz ~]# sleep 4000 //^Z,将前台的程序挂起(暂停)到后台[2]+ Stopped sleep 4000[root@lqz ~]# ps aux |grep sleep[root@lqz ~]# jobs //查看后台作业[1]- Running sleep 3000 &[2]+ Stopped sleep 4000[root@lqz ~]# bg %2 //让作业 2 在后台运行[root@lqz ~]# fg %1 //将作业 1 调回到前台[root@lqz ~]# kill %1 //kill 1,终止 PID 为 1 的进程[root@lqz ~]# (while :; do date; sleep 2; done) & //进程在后台运行,但输出依然在当前终端[root@lqz ~]# (while :; do date; sleep 2; done) &>/dev/null &
2.screen的使用(强烈推荐,生产必用)
#1.安装[root@oldboy ~]# yum install screen -y#2.开启一个screen窗口,指定名称[root@oldboy ~]# screen -S wget_mysql#3.在screen窗口中执行任务即可[root@oldboy ~]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.30-linux-glibc2.12-x86_64.tar.gz --no-check-certificate#4.平滑的退出screen,但不会终止screen中的任务。注意: 如果使用exit 才算真的关闭screen窗口ctrl+a+d#5.查看当前正在运行的screen有哪些[root@oldboy ~]# screen -listThere is a screen on:22058.wget_mysql (Detached)1 Socket in /var/run/screen/S-root.#6.进入正在运行的screen[root@oldboy ~]# screen -r wget_mysql[root@oldboy ~]# screen -r 22058#7 终止(ctrl+d),退出才能停止screenexit
前台作业:一直占用终端的作业
后台作业:不占用当前的终端
让作业运行于后台:
ctrl+z 对于启动中
command & 也会输出到终端,还是会终端显示
nohup ping www.baidu.com &
脱离终端:
nohup command &>/dev/null &(黑洞)
nohup ping www.baidu.com &>/dev/null &
screen
--r 进入
6.进程的优先级[进阶]
1.什么优先级
优先级指的是优先享受资源,比如排队买票时,军人优先、老人优先。等等
2.为什么要有系统优先级
举个例子: 海底捞火锅正常情况下响应就特别快,那么当节假日来临时人员突增则会导致处理请求特别慢,那么假设我是海底捞VIP客户(最高优先级),无论门店多么繁忙,我都不用排队,海底捞人员会直接服务于我,满足我的需求。至于没有VIP的人员(较低优先级)则进入排队等待状态。(PS: 至于等多久,那…..)
3.系统中如何给进程配置优先级?
在启动进程时,为不同的进程使用不同的调度策略。 nice 值越高: 表示优先级越低,例如+19,该进程容易将CPU 使用量让给其他进程。 nice 值越低: 表示优先级越高,例如-20,该进程更不倾向于让出CPU。
1.使用top或ps命令查看进程的优先级
#1.使用top可以查看nice优先级。NI: 实际nice级别,默认是0。PR: 显示nice值,-20映射到0,+19映射到39PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND1083 root 20 0 298628 2808 1544 S 0.3 0.1 2:49.28 vmtoolsd5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:+#2.使用ps查看进程优先级[root@m01 ~]# ps axo command,nice |grep sshd|grep -v grep/usr/sbin/sshd -D 0sshd: root@pts/2 0
2. nice指定程序的优先级。语法格式 nice -n 优先级数字 进程名称
#1.开启vim并且指定程序优先级为-5[root@m01 ~]# nice -n -5 vim &[1] 98417#2.查看该进程的优先级情况[root@m01 ~]# ps axo pid,command,nice |grep 98417
98417 vim
-5
3.renice命令修改一个正在运行的进程优先级。语法格式 renice -n 优先级数字 进程pid
#1.查看sshd进程当前的优先级状态[root@m01 ~]# ps axo pid,command,nice |grep 折叠shd
70840 sshd: root@pts/2 0
98002 /usr/sbin/sshd -D 0
#2.调整sshd主进程的优先级[root@m01 ~]# renice -n -20 9800298002 (process ID) old priority 0, new priority -20#3.调整之后记得退出终端[root@m01 ~]# ps axo pid,command,nice |grep 折叠shd
70840 sshd: root@pts/2 0
98002 /usr/sbin/sshd -D -20
[root@m01 ~]# exit#4.当再次登陆sshd服务,会由主进程fork子进程(那么子进程会继承主进程的优先级)[root@m01 ~]# ps axo pid,command,nice |grep 折叠shd
98002 /usr/sbin/sshd -D -20
98122 sshd: root@pts/0 -20
生产案例、Linux出现假死,怎么办,又如何通过nice解决?
7.系统平均负载[进阶]
每次发现系统变慢时,我们通常做的第一件事,就是执行 top 或者 uptime 命令,来了解系统的负载情况。比如像下面这样,我在命令行里输入了 uptime 命令,系统也随即给出了结果。
[root@m01 ~]# uptime
04:49:26 up 2 days, 2:33, 2 users, load average: 0.70, 0.04, 0.05
#我们已经比较熟悉前面几列,它们分别是当前时间、系统运行时间以及正在登录用户数。# 而最后三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)。
1.什么是平均负载
平均负载不就是单位时间内的 CPU 使用率吗?上面的 0.70,就代表 CPU 使用率是 70%。其实上并….. 那到底如何理解平均负载: 平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数, PS: 平均负载与 CPU 使用率并没有直接关系。
2.可运行状态和不可中断状态是什么
1.可运行状态进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们ps 命令看到处于 R 状态的进程。
2.不可中断进程,(你做什么事情的时候是不能打断的?) 系统中最常见的是等待硬件设备的 I/O 响应,也就是我们ps 命令中看到的 D 状态(也称为 Disk Sleep)的进程。
例如: 当一个进程向磁盘读写数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断的,这个时候的进程就处于不可中断状态。如果此时的进程被打断了,就容易出现磁盘数据与进程数据不一致的问题。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。
划重点,因此你可以简单理解为,平均负载其实就是单位时间内的活跃进程数。
3.那平均负载为多少时合理
最理想的状态是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。所以在评判平均负载时,首先你要知道系统有几个 CPU,这可以通过 top 命令获取,或grep 'model name' /proc/cpuinfo
例1、假设现在在 4、2、1核的CPU上,如果平均负载为 2 时,意味着什么呢?
Q1.在4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
Q2.在2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
Q3.而1 个 CPU 的系统上,则意味着有一半的进程竞争不到 CPU。
PS: 平均负载有三个数值,我们应该关注哪个呢?
实际上,我们都需要关注。就好比上海4月的天气,如果只看晚上天气,感觉在过冬天呢。但如果你结合了早上、中午、晚上三个时间点的温度来看,基本就可以全方位了解这一天的天气情况了。
1.如果 1 分钟、5 分钟、15 分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
2.但如果 1 分钟的值远小于 15 分钟的值,就说明系统最近 1 分钟的负载在减少,而过去 15 分钟内却有很大的负载。
3.反过来,如果 1 分钟的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续上升,所以就需要持续观察。
PS: 一旦 1 分钟的平均负载接近或超过了 CPU 的个数,就意味着系统正在发生过载的问题,这时就得分析问题,并要想办法优化了
在来看个例子3、假设我们在有2个 CPU 系统上看到平均负载为 2.73,6.90,12.98
那么说明在过去1 分钟内,系统有 136% 的超载 (2.73/2=136%)
而在过去 5 分钟内,有 345% 的超载 (6.90/2=345%)
而在过去15 分钟内,有 649% 的超载,(12.98/2=649%)
但从整体趋势来看,系统的负载是在逐步的降低。
4.那么在实际生产环境中,平均负载多高时,需要我们重点关注呢?
当平均负载高于 CPU 数量 70% 的时候,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。
但 70% 这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。当发现负载有明显升高趋势时,比如说负载翻倍了,你再去做分析和调查。
5.平均负载与 CPU 使用率有什么关系
在实际工作中,我们经常容易把平均负载和 CPU 使用率混淆,所以在这里,我也做一个区分。可能你会疑惑,既然平均负载代表的是活跃进程数,那平均负载高了,不就意味着 CPU 使用率高吗?
我们还是要回到平均负载的含义上来,平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
6.平均负载案例分析实战
下面,我们以三个示例分别来看这三种情况,并用 stress、mpstat、pidstat 等工具,找出平均负载升高的根源。
stress 是 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
mpstat 是多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
#如果出现无法使用mpstat、pidstat命令查看%wait指标建议更新下软件包 wget http://pagesperso-orange.fr/sebastien.godard/sysstat-11.7.3-1.x86_64.rpm rpm -Uvh sysstat-11.7.3-1.x86_64.rpm
场景一:CPU 密集型进程
1.首先,我们在第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
[root@m01 ~]# stress --cpu 1 --timeout 600
2.接着,在第二个终端运行 uptime 查看平均负载的变化情况
# 使用watch -d 参数表示高亮显示变化的区域(注意负载会持续升高) [root@m01 ~]# watch -d uptime 17:27:44 up 2 days, 3:11, 3 users, load average: 1.10, 0.30, 0.17
3.最后,在第三个终端运行 mpstat 查看 CPU 使用率的变化情况
# -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据[root@m01 ~]# mpstat -P ALL 5Linux 3.10.0-957.1.3.el7.x86_64 (m01) 2019年04月29日 _x86_64_ (1 CPU)17时32分03秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle17时32分08秒 all 99.80 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.0017时32分08秒 0 99.80 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00
#单核CPU所以只有一个all和0
4.从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。那么,到底是哪个进程导致了 CPU 使用率为 100% 呢?可以使用 pidstat 来查询
# 间隔 5 秒后输出一组数据[root@m01 ~]# pidstat -u 5 1Linux 3.10.0-957.1.3.el7.x86_64 (m01) 2019年04月29日 _x86_64_(1 CPU)17时33分21秒 UID PID %usr %system %guest %CPU CPU Command17时33分26秒 0 110019 98.80 0.00 0.00 98.80 0 stress#从这里可以明显看到,stress 进程的 CPU 使用率为 100%。
场景二:I/O 密集型进程
1.首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync
[root@m01 ~]# stress --io 1 --timeout 600s
2.然后在第二个终端运行 uptime 查看平均负载的变化情况:
[root@m01 ~]# watch -d uptime 18:43:51 up 2 days, 4:27, 3 users, load average: 1.12, 0.65, 0.00
3.最后第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
# 显示所有 CPU 的指标,并在间隔 5 秒输出一组数据[root@m01 ~]# mpstat -P ALL 5Linux 3.10.0-693.2.2.el7.x86_64 (bgx.com) 2019年05月07日 _x86_64_ (1 CPU)14时20分07秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle14时20分12秒 all 0.20 0.00 82.45 17.35 0.00 0.00 0.00 0.00 0.00 0.0014时20分12秒 0 0.20 0.00 82.45 17.35 0.00 0.00 0.00 0.00 0.00 0.00#会发现cpu的与内核打交道的sys占用非常高
4.那么到底是哪个进程,导致 iowait 这么高呢?我们还是用 pidstat 来查询
# 间隔 5 秒后输出一组数据,-u 表示 CPU 指标[root@m01 ~]# pidstat -u 5 1Linux 3.10.0-957.1.3.el7.x86_64 (m01) 2019年04月29日 _x86_64_(1 CPU)18时29分37秒 UID PID %usr %system %guest %wait %CPU CPU Command18时29分42秒 0 127259 32.60 0.20 0.00 67.20 32.80 0 stress18时29分42秒 0 127261 4.60 28.20 0.00 67.20 32.80 0 stress18时29分42秒 0 127262 4.20 28.60 0.00 67.20 32.80 0 stress#可以发现,还是 stress 进程导致的。
场景三:大量进程的场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
1.首先,我们还是使用 stress,但这次模拟的是 4 个进程
[root@m01 ~]# stress -c 4 --timeout 600
2.由于系统只有 1 个 CPU,明显比 4 个进程要少得多,因而,系统的 CPU 处于严重过载状态
[root@m01 ~]# watch -d uptime 19:11:07 up 2 days, 4:45, 3 users, load average: 4.65, 2.65, 4.65
3.然后,再运行 pidstat 来看一下进程的情况:
# 间隔 5 秒后输出一组数据[root@m01 ~] # pidstat -u 5 1 平均时间: UID PID %usr %system %guest %wait %CPU CPU Command 平均时间: 0 130290 24.55 0.00 0.00 75.25 24.55 - stress 平均时间: 0 130291 24.95 0.00 0.00 75.25 24.95 - stress 平均时间: 0 130292 24.95 0.00 0.00 75.25 24.95 - stress 平均时间: 0 130293 24.75 0.00 0.00 74.65 24.75 - stress
可以看出,4 个进程在争抢 1 个 CPU,每个进程等待 CPU 的时间(也就是代码块中的 %wait 列)高达 75%。这些超出 CPU 计算能力的进程,最终导致 CPU 过载。
分析完这三个案例,我再来归纳一下平均负载与CPU
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源
安全
防火墙
绿盟
深信服
启明星辰
飞塔
思科
华为
华三
(网关处的硬件防火墙)
4表5链 iptables -L 查看 防火墙策略 iptables -F 清空 防火墙 systemctl disable firewalld 开机并启动 systemctl stop firewalled
selinux
美国国家安全局
配置文件 /etc/selinux/config
SELINUX=disabled # 关掉防火墙
setenforce 0 临时生效
getenforce 查看selinux的状态
红帽认证:
rhcea
rhce
rhca
思考认证:
ccnp
ccie
ccia
orcal认证:
ocp
链接:https://www.cnblogs.com/coderxueshan/p/17950646
(版权归原作者所有,侵删)








发表评论